All information in OME revolves around a data structure
called the object hierarchy. This hierarchy defines
four kinds of objects — projects, datasets, images, and
features — and an organizational structure for grouping these
objects together. This structure is shown in Figure 1.
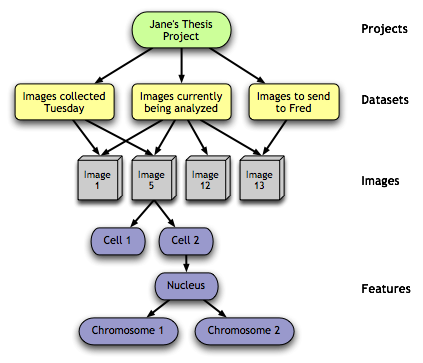
Figure 1: Object hierarchy
At the top of the object hierarchy is the project.
Projects represent a large, long-term investigation, usually
by either a single OME user or a small collection of users in
the same research group.
Each project contain a number of datasets. Projects
and datasets form a many-to-many relationship; a project can
contain more than one dataset, and each dataset can belong to
more than one project. Most analysis routines are performed
at the dataset level. This provides both a convenient batch
processing capability, and the ability to calculate aggregate
information about the contents of a dataset.
Each dataset contains a number of images. Like
projects, images form a many-to-many relationship with
datasets. Images in OME are inherently multi-dimensional —
they consist of pixels across the usual three spatial
dimensions, and can include multiple color channels and time
series.
Finally, OME images can be segmented, usually via a
computational analysis routine, into a tree
of features. Features represent any logical
subdivision of an image. Nothing is predefined, everything is
arbitrary: the method used to find features, the information
needed to distinguish one feature from another and from the
background of the image, and what the features logically
represent. The only constraint is that the features in an
image must form a proper tree.