Spreadsheet Importer
Spreadsheet Importer
This annotator can handle bulk annotation by CategoryGroups and SemanticTypes. For the script to execute properly, the file you upload must be in the proper format. Failure to have the file in the right format will result in incorrect annotation. You can input two types of files for annotation: tab-delimited text files and Microsoft Excel spreadsheets.
|
|
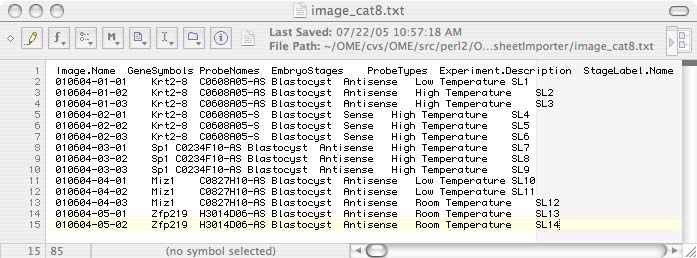
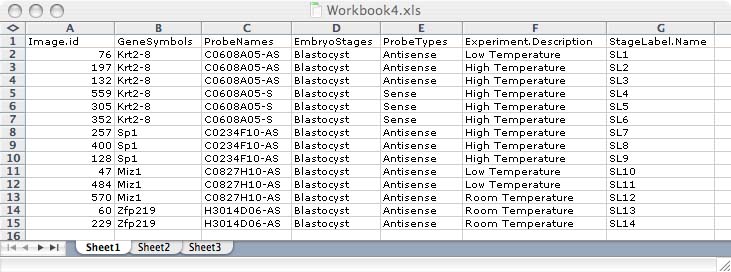
The column headings dictate what type of annotation will take place. To annotate by CategoryGroup, you can just type the name of the CategoryGroup that you would like to create or that already exists for the column name. The entries in the columns are the Categories that already exist or that will be created.
To annotate by SemanticType, the column headings should be of the form SemanticType.SemanticElement and the entry in each column should be the SemanticElement's value. Please be sure to start your spreadsheet at row 1, column 1 and on the first Worksheet (if you are using Excel).
If you are annotating images, one of the columns must be named "Image.Name", "Image.FilePath", "Image.FileSHA1", or "Image.id". Do not use more than one column with these names!. This image specification is how OME finds the correct image to annotate. It is an error if the image specification results in more than one image, and using Image.id is the only way to guarantee that. Unfortunately, its not very convenient to use. Image.Name can be used if you are sure that Image names are unique (Image names normally don't have a file extension). When files are imported to make OME Images, the full file paths are stored and associated with the Images. Instead of Image.id or Image.Name, you can use Image.FilePath, to match one of the files used to construct the Image. Besides the file path, OME also stores a SHA1 digest for each file it imports, so instead of matching paths, you can match SHA1 digests using Image.FileSHA1. A SHA1 digest is unique for a file regardless of what the file is called, or what directory its in. A SHA1 digest can be computed on any file with the UNIX command:
openssl sha1 -hex anyFile.foo
You aren't limited to annotating images. You could simply add Categories, CategoryGroups, or attributes of SemanticTypes to the database. These will be global annotations. You cannot create image annotations (i.e. annotations with SemanticTypes of granularity 'I') without an image specification (i.e. Image.id, Image.Name, etc)
If there are columns you would like to have for your own notes that the importer should ignore and not be confused by (for example an Image.id column and an Image.Name column), preface the column name with a '#' (e.g. #Image.Name)